
觀察值 & 變數
組成:觀察值&變數>資料集
了解資料,才能進行有效的資料處理與統計分析
Contents
觀察值 – Observations
SAS的資料是由觀察值與變數組成,觀察值又可以稱為列(Row)、Record。
觀察值是用來儲存對應變數下的值,它所能儲存的格式依照變數而定。
變數 – Variables
SAS的資料是由觀察值與變數組成,變數又可以稱為欄位(Columns)、Field。
變數是用來表示與儲存觀察值的特質。
例如:有11位學生,我想用「sex」來記錄這群人的性別,這個sex就是變數,而在下方的「1」則是每位學生(觀察值)性別的紀錄
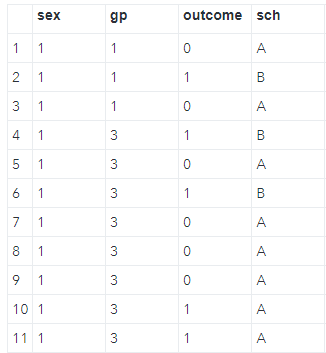
🙋🙋♂️試問,上面有幾個變數?
💡請反白*共有4個:sex、gp、outcome、sch*
類型
數值型 – Numeric
觀察值位元組:2~8
文字型 – Character
觀察值位元組:1~32767
🙋🙋♂️那像是1這種數字可以儲存到文字型變數嗎?
💡問得好,當然可以!
🙋🙋♂️那下面的No跟Score變數是數值型還是文字型變數?
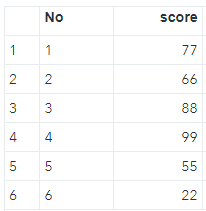
💡No是文字型變數;Score是數值型變數
※有個簡單的辨別方式,大部分情況下適用,在SAS中文字型變數會靠左對齊,數值型變數會靠右對齊。
命名規則
又到了熟悉的命名規則環節,經歷了資料集與資料館後,現在要介紹變數的命名規則。
- 需以英文字母或底線開頭,大小寫不拘
- 後面可以是英文字母、底線或數字混合
- 長度最大為32 Bytes (與資料集相同)
- 不可使用_N_、_Error_、_Numeric、_Character_、_All_命名,這些屬於SAS變數的保留名稱
標籤 – Label
有時候,受限於變數的32 Bytes限制,不能去建立一個我們所想要的變數名稱,這時標籤就派上用場了!
它僅影響SAS打印時,我們所看到的樣貌,並不會影響觀察值本身。
Data test;
sex1="";
sex2="";
sex3="";
sex4="";
label sex2=Gender
sex3=12345,678910,1112131415,1617181920
sex4="性別"
;
run;上方這是一段建立3種不同類型標籤的語法,使用Label敘述句。
結果:
| 變數 | 標籤 |
| 這是顯示原始變數名稱的資料表 | 這是套用標籤後的變數,標籤可以突破32 Bytes的上限(最長256 Bytes),並且也可以使用中文,這易於我們分辨變數原本的意義 |
屬性 – Attributes
屬性是指構成變數的所有事物,包含Name、Type、Length、Format、Informat、Label、Index Type。
| Name | 變數的名稱 |
| Type | 辨別變數是數值型或是文字型 |
| Length | 變數儲存觀察值的長度,因數值型與文字型而不同 |
| Format | SAS打印觀察值時表現的格式,因數值型與文字型而不同 |
| Informat | SAS讀取觀察值時表現的格式,如果Informat小於所讀取的觀察值,會造成該筆資料被截斷 |
| Label | SAS打印變數時的描述性資訊 |
| Index Type | 紀錄此變數是否為索引與索引類型 |
下面這段語法是查詢指定資料集(sashelp.cars)變數的屬性:
proc contents data=sashelp.cars details;
run;執行後在結果中我們可以找到如下表格,可以用來確認所有變數的屬性:(自動依照資料表擁有屬性列出)
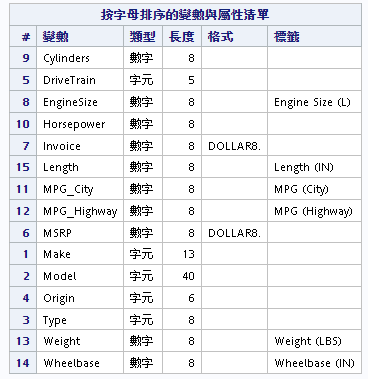
※其他方法
- SAS Base、Enterprise Guide、SAS Studio直接點選資料集欄位
- SAS Viya<管理環境><資料>
- 語法:Dictionary Tables & Views、Proc Dataset
自動變數 – Automatic Variables
SAS系統自動產生的變數,只能在特定情形下使用,無法去更改變數名稱。
以下概列較常使用的自動變數與功能簡介,之後會再整理一篇所有自動變數的資訊與應用:
_N_
紀錄當前PDV資料集是第幾筆觀察值,第1筆即為1
Data _Null_;
input No $ Age;
put _N_ No= Age=;
cards;
1 19
2 23
3 17
4 21
5 22
;
run; 上面語法中,這邊先關注「put _N_ No= Age=;」這行,其他語法是用來建立資料的。
Put敘述句的功能是用來將資料打印到SAS 日誌中,執行後日誌結果如下:
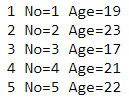
- 最前面的1~5正是_N_,第1筆觀察值對應的_N_為1,以此類推
_Error_
紀錄目前程式執行過程出現的錯誤,0為無錯誤
Data _Null_;
input No $ Age;
put _N_= _Error_=;
cards;
1 DD
2 23
3 17
4 21
5 22
;
run; 上面語法中,我們關注「put _N_= _Error_=」這行,「_N_」與「_N_=」的差別在於日誌上是否會出現「_N_=」。
執行後日誌結果如下:
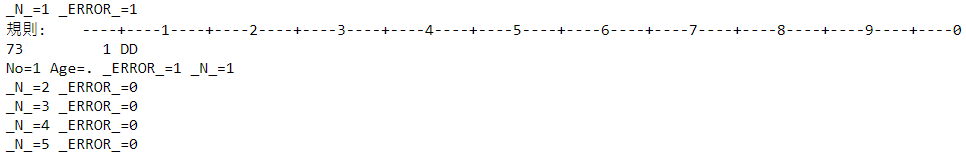
- 因為在cards;後的第1行中輸入了不符合變數(Age:數值)格式的觀察值,所以在第1筆觀察值結束時,PDV的_Error_被更改為1(表示有錯誤)
- 在第2筆觀察值時,因為此時PDV會重設_Error_,而第2~5筆並沒有錯誤,所以才看到_Error_都為0
_Numeric_
等同於該資料集所有的數值型變數,在只需要針對數值型操作時很方便
Data test;
input No $ Score1 Score2;
array num_old{*} _Numeric_ ;
array num_new{*} new_Score1-new_Score2;
do i=1 to 2;
num_new[i]=num_old[i]+10;
end;
cards;
1 59 77
2 46 31
3 81 58
4 46 89
5 71 72
;
run;這段語法中,主要目的是建立2個矩陣,分別儲存原本的「Score1、Score2」數值變數以及新的數值變數「new_Score1、new_Score2」
我們關注「array num_old{*} _Numeric_;」與「num_new[i]=num_old[i]+10;」這2行,num_new[]。
- 「array num_old{*} _Numeric_;」:建立一個名為num_old的矩陣,裡面存放所有的數值變數
- 「num_new[i]=num_old[i]+10;」:將原本在num_old矩陣中的所有數值變數加10後,存至新的變數中
執行後輸出資料結果如下:

_Character_
等同於該資料集所有的文字型變數,在只需要針對文字型操作時很方便
Data test;
input No $ male $ female $;
array char_old{*} $ _character_ ;
array char_new{*} $20 new_male new_female;
do i=1 to 2;
char_new[i]=cats("Prefix-", char_old[i], "-Suffix");
end;
cards;
1 Andy Viola
2 Jonny Aly
3 Nicola Melissa
;
run; 這段語法中,主要目的是建立2個矩陣,分別儲存原本的「male、female」文字變數以及新的文字變數「new_male、new_female」
我們關注「array char_old{*} $ character ;」與「char_new[i]=cats(“Prefix-“, char_old[i], “-Suffix”);」這2行
- 「array char_old{*} $ character ;」:建立一個名為char_old的矩陣,裡面存放所有的文字變數
- 「char_new[i]=cats(“Prefix-“, char_old[i], “-Suffix”);」:將原本在char_old矩陣中的所有數值變數加入前綴與後綴後,存至新的變數中
執行後輸出資料結果如下:

_All_
等同於該資料集所有的變數,在需要針對所有變數或是將變數儲存至矩陣時很方便
Data test;
input No $ male $ female $;
put _all_;
cards;
1 Andy Viola
2 Jonny Aly
3 Nicola Melissa
;
run;執行後日誌結果如下:
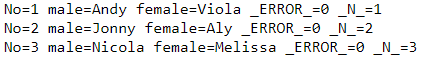
- 日誌中把所有的變數以及_Error_、_N_這2個自動變數都打印出來,並且是以「XX=」的形式出現
參考資料:

謝謝閱讀這篇文章,有問題歡迎在下方留言
