雖然我在這個部落格的第一篇文章就介紹了Data Step,但那篇更多的是關於Data Step背後的運作原理,有興趣的人歡迎去看這篇【01】SAS初學者指南|從Data Step開始
而這一篇主要是介紹Data Step常用的基礎語法,更多的是關於實作方面,比較進階的語法之後會另外寫成主題式文章
基本架構
Data Step基礎語法由data、run以及其他敘述句所組成
以下有幾點關於Data Step語法的小知識
- 每個敘述句後面必須加上「分號(;)」
- SAS Dataset與變數有特殊的命名規則(詳見【02】與【03】)
- SAS語法不分大小寫,但在單引號(‘)、雙引號(“)以及cards/datalines 敘述句為例外
data /*建立資料 (Data set Options)*/;
/*來源資料 (Data set Options | Options)*/
/*基礎常用敘述句、函數及自動變數*/
-----Implicit-Output 敘述句-----
run;接下來會以依序按照「建立資料」、「來源資料」、「基礎常用敘述句、函數及自動變數」、「Implicit-Output敘述句」架構來進行介紹,由於內容過長所以分為上下兩篇,本篇介紹「建立資料」與「來源資料」兩部分
建立資料
大部分情形下只會建立1個資料集,也就是建立1個SAS Dataset的意思,但偶爾涉及複雜的資料處理時,會同時建立多個SAS Dataset
1個SAS Dataset
data one;
set sashelp.cars;
run;- data敘述句後方放入1個SAS Dataset名稱「one」
- 這邊暫以sashelp.cars作為來源(此為內建資料集)
- 最後加上1個run敘述句
執行程式後,就會順利建立1個SAS Dataset
多個SAS Dataset
data one two three;
set sashelp.cars;
run;- data敘述句後方放入多個SAS Dataset名稱,中間以空白作為間隔「one two three」
- 這邊暫以sashelp.cars作為來源(此為內建資料集)
- 最後加上1個run敘述句
執行程式後,就會順利建立多個SAS Dataset
但其實這種建立多個相同資料的SAS Dataset比較少見,除非需要特別備份相同資料到另一個地方
當過程中需要依照條件或步驟輸出不同資料集時,則會同時建立多個SAS Dataset
data cars_Asia cars_Europe cars_USA;
set sashelp.cars;
if origin="Asia" then output cars_Asia;
else if origin="Europe" then output cars_Europe;
else if origin="USA" then output cars_USA;
run;- data敘述句後方放入多個SAS Dataset名稱,中間以空白作為間隔
- 以sashelp.cars作為來源
- 這邊使用If敘述句與output敘述句來輸出不同資料(依據origin欄位輸出)
- 最後加上1個run敘述句
執行程式後,就會順利建立多個SAS Dataset,並且每個資料集都並不相同

Data Set Options
在data敘述句中可以為SAS Dataset加上Options,稱之為Data Set Options,並且如果是多個SAS Dataset可以有不同的Options,互不干擾
常用的data敘述句 – Data Set Options
| Data Set Options | 說明 |
| Keep= | 限制SAS Dataset保留指定的變數 |
| Drop= | 限制SAS Dataset刪除指定的變數 |
| Label= | 為SAS Dataset加上標籤 |
| Where= | 進行篩選後建立SAS Dataset |
Keep
data test (keep=Make Origin MSRP);
set sashelp.cars;
run;- data敘述句後方先放入SAS Dataset名稱
- 在SAS Dataset名稱與分號之間輸入1對「括弧()」
- 在括弧中輸入「keep=」
- 在keep=後方輸入要保留的變數,以空白間隔
Drop
data test (drop=MPG_City MPG_Highway);
set sashelp.cars;
run;- data敘述句後方先放入SAS Dataset名稱
- 在SAS Dataset名稱與分號之間輸入1對「括弧()」
- 在括弧中輸入「drop=」
- 在drop=後方輸入要移除的變數,以空白間隔
Label
data test (label="測試用資料集");
set sashelp.cars;
run;- data敘述句後方先放入SAS Dataset名稱
- 在SAS Dataset名稱與分號之間輸入1對「括弧()」
- 在括弧中輸入「label=」
- 在label=後方輸入一對單引號(‘)或雙引號(“)
- 在引號中放入作為SAS Dataset的標籤名稱
使用以下這個語法就能看到資料集的標籤
proc contents data=test;
run;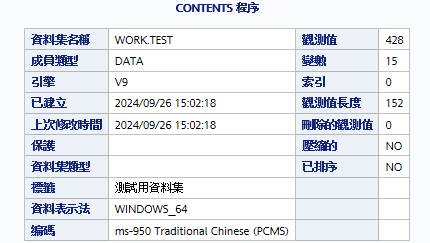
Where
data test (where=( Origin="Asia" ));
set sashelp.cars;
run;- data敘述句後方先放入SAS Dataset名稱
- 在SAS Dataset名稱與分號之間輸入1對「括弧()」
- 在括弧中輸入「where=」
- 在where=後方再次輸入1對「括弧()」
- 在括弧中輸入「運算式」,決定篩選的條件

來源資料
雖然先前的範例都是使用Set敘述句,但其實還有Input與Infile敘述句可以使用
不過他們所讀取的資料並不相同:
- Set敘述句是用來讀取SAS Dataset
- Input敘述句是用來讀取Raw Data
- Infile敘述句是用來讀取文字檔的資料(例如:txt, csv),在讀取資料時需與Input敘述句搭配使用
1個SAS Dataset
data test;
set sashelp.cars;
run;- data敘述句後方放入SAS Dataset名稱
- 使用set敘述句來讀取1個SAS Dataset
- 最後加上1個run敘述句
執行程式後,就會順利使用set敘述句來讀取「sashelp.cars」這1個SAS Dataset
多個SAS Dataset
data cars;
set cars_Asia cars_Europe cars_USA;
run;- data敘述句後方放入SAS Dataset名稱
- 使用set敘述句來讀取多個SAS Dataset,中間以空白作為間隔「cars_Asia cars_Europe cars_USA」
- 最後加上1個run敘述句
執行程式後,就會順利使用set敘述句來讀取「cars_Asia cars_Europe cars_USA」這3個SAS Dataset
Data Set Options
在set敘述句中可以為SAS Dataset加上Options,稱之為Data Set Options,並且如果是多個SAS Dataset可以有不同的Options,互不干擾
常用的set敘述句 – Data Set Options
| Data Set Options | 說明 |
| FirstObs= | 從第nth筆觀察值開始讀取 |
| Obs= | 讀取到第nth筆觀察值 |
| Keep= | 限制SAS Dataset讀取時保留指定的變數 |
| Drop= | 限制SAS Dataset讀取時刪除指定的變數 |
| Where= | 在讀取SAS Dataset時進行篩選 |
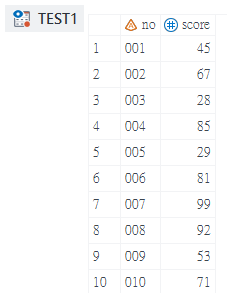
FirstObs
data test1;
input no $ score @@;
cards;
001 45 002 67 003 28 004 85 005 29
006 81 007 99 008 92 009 53 010 71
;
data test2;
set test1(firstobs=5);
run;- 先建立test1示範資料集,包含001~010共10筆資料
- data敘述句後方放入要建立的SAS Dataset名稱
- set敘述句後方先放入要讀取的SAS Dataset
- 在SAS Dataset名稱與分號之間輸入1對「括弧()」
- 在括弧中輸入「firstobs=5」
- 程式執行完成後test2這個SAS Dataset的第一筆為test1的第5筆資料,因為是從第5筆開始讀取
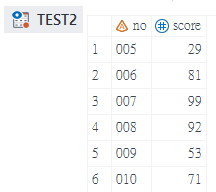
Obs
data test1;
input no $ score @@;
cards;
001 45 002 67 003 28 004 85 005 29
006 81 007 99 008 92 009 53 010 71
;
data test2;
set test1(obs=5);
run;- 先建立test1示範資料集,包含001~010共10筆資料
- data敘述句後方放入要建立的SAS Dataset名稱
- set敘述句後方先放入要讀取的SAS Dataset
- 在SAS Dataset名稱與分號之間輸入1對「括弧()」
- 在括弧中輸入「obs=5」
- 程式執行完成後test2這個SAS Dataset的最後一筆為test1的第5筆資料,因為只讀取到第5筆資料
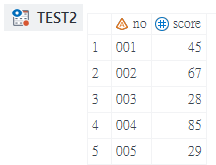
而Firstobs與Obs可以與搭配使用,用來指定要讀取的資料列範圍
data test1;
input no $ score @@;
cards;
001 45 002 67 003 28 004 85 005 29
006 81 007 99 008 92 009 53 010 71
;
data test2;
set test1(firstobs=5 obs=8);
run;- 先建立test1示範資料集,包含001~010共10筆資料
- data敘述句後方放入要建立的SAS Dataset名稱
- set敘述句後方先放入要讀取的SAS Dataset
- 在SAS Dataset名稱與分號之間輸入1對「括弧()」
- 在括弧中輸入「firstobs=5」與「obs=8」
- 程式執行完成後test2這個SAS Dataset的最後一筆為test1的第5筆資料,最後一筆為test1的第8筆資料,意即讀取第5~8筆資料,總共4筆
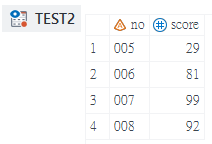
Keep
data test;
set sashelp.cars(keep=Make Origin MSRP);
run;- data敘述句後方放入SAS Dataset名稱
- set敘述句後方先放入要讀取的SAS Dataset
- 在SAS Dataset名稱與分號之間輸入1對「括弧()」
- 在括弧中輸入「keep=」
- 在keep=後方輸入讀取時要保留的變數,以空白間隔
- 最後test2只會有3個變數
Drop
data test;
set sashelp.cars(drop=MPG_City MPG_Highway);
run;- data敘述句後方放入SAS Dataset名稱
- set敘述句後方先放入要讀取的SAS Dataset
- 在SAS Dataset名稱與分號之間輸入1對「括弧()」
- 在括弧中輸入「drop=」
- 在drop=後方輸入讀取時要移除的變數,以空白間隔
- 最後test2則不會有MPG_City、MPG_Highway這兩個變數
Where
data test;
set sashelp.cars(where=( Origin="Asia" ));
run;- data敘述句後方放入SAS Dataset名稱
- set敘述句後方先放入要讀取的SAS Dataset
- 在SAS Dataset名稱與分號之間輸入1對「括弧()」
- 在括弧中輸入「where=」
- 在where=後方再次輸入1對「括弧()」
- 在括弧中輸入「運算式」,決定讀取時的篩選條件
日誌中會特別看到WHERE Origin=’Asia’這句被打印出來

Input敘述句
Input敘述句在用來讀取資料時,必須搭配cards或datalines敘述句進行使用
cards與datalines敘述句在使用上為等價的,它是用來標記要使用Input敘述句讀取的資料列
data test;
input No $ A1 B1 C1;
cards;
001 56 71 49
002 76 52 81
003 92 74 88
;
run;- data敘述句後方放入SAS Dataset名稱
- input敘述句放入在後面cards敘述句中要建立的變數,其中如果要讀取的資料是文字變數,需在後方加上1個「$」符號
- 接著輸入cards敘述句(包含分號;)後跳下一行
- 以列的方式輸入資料,不同變數間以空白間隔,當資料輸入完成後跳下一行
- 輸入1個「分號;」
- 最後加上1個run敘述句
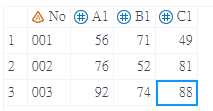
Arguments – @ V.S @@
偶爾會看到他人語法在Input使用這兩個符號,它們能幫助我們更好控制讀取資料的方式
@:用來告訴SAS「在當前的Input敘述句」後面還有Input敘述句,要把目前這一筆觀察值的PDV值保留到下一個Input敘述句進行使用
@@:用來告訴SAS「接在cards或datalines敘述句後面的資料,不再以行區分每一筆觀察值,而是在讀取足夠的變數後自動往右繼續讀取下一筆觀察值」,簡單來說就是不侷限每一筆觀察值只能一行一行輸入的方式
※@與@@在使用時,皆需要放在Input敘述句的最後方。
下面是@的範例:
data test;
input Gender $ @;
if Gender="F" then
do;
input Height $;
Weight="secret";
end;
else if Gender="M" then
do;
input Height $ Weight $;
end;
cards;
F Mary 163
M Tom 173 68
M Lion 179 81
F Amy 156
;
run;- 第一個Input敘述句先讀取Gender這個變數,最後方放入@參數
- 如果Gender的值是F,只讀入Height變數,而Weight變數則統一賦予相同的值”secret”
- 如果Gender的值是M,則讀入Height、Weight變數
下面是@@的範例:
data test;
input No $ A1 B1 C1 @@;
cards;
001 56 71 49 002 76 52 81 003 92 74 88
;
run;- Input敘述句中共有No、A1、B1、C1這四個變數要讀取,最後方加入@@參數
- 首先讀取第一筆觀察值「001 56 71 49」,此時已讀取足夠的四個變數,接著下一個值SAS會自動調整為第二筆觀察值「002 76 52 81」,繼續向右讀取所有資料直到結束
Input方式
Input敘述句在使用上分為4種方法,剛剛所使用的是List Input,其他還有Column Input、Formatted Input以及Named Input
List input
使用掃描的方法去讀資料,但資料必須間隔至少1個空白(如果是其他間隔符號則需要搭配Infile敘述句使用)
只需在Input敘述句後方依序加上cards敘述句下的變數,是使用上最輕鬆的方法
data test;
input No $ A1 B1 C1;
cards;
001 56 71 49
002 76 52 81
003 92 74 88
;
run;非空白的間隔符號(Input敘述句搭配Infile敘述句使用,以下使用逗號為範例)
data test;
infile cards DLM=",";
input No $ A1 B1 C1;
cards;
001,56,71,49
002,76,52,81
003,92,74,88
;
run;- 新增1個Infile敘述句
- 在Infile與分號之間先輸入「cards」,表示Infile敘述句要套用的是cards敘述句(如果今天是使用Datalines,同理)
- 接著繼續在Infile與分號之間輸入「DLM=」
- 在DLM=後輸入以單引號或雙引號包裹起來的分隔符號「’,’」
Column Input
能用來讀取標準化的資料,需要指定每一個變數的起始位置與結束位置
data test;
infile cards DLM=",";
input Name_Male $ 1-15 Number 17-20 Name_Female $ 22-40;
cards;
LOUIE BLACKWELL, 76,ALI DALTON
CADE NIXON , 123,GABRIELLA MCKAY
QUINCY STARK ,6843,JOSIE LOPEZ
;
run;- 首先檢查要輸入的資料,每筆觀察值的分隔位置是不是相同的
- 在Input敘述句後同樣先輸入變數名稱,接著確認是否為文字變數(若是,加上1個$)
- 在「Name_Male $」後方輸入1-15,這表示每一筆觀察值的Name_Male都從第1個位置讀取到第15個位置
- 在「Number」後方輸入17-20,這表示每一筆觀察值的Number都從第17個位置讀取到第20個位置
- 在「Name_Female $」後方輸入22-40,這表示每一筆觀察值的Name_Female都從第22個位置讀取到第40個位置
Formatted Input
與Column Input類似,但它也可以用來讀取非標準化的資料,需要額外使用pointer-controls來控制讀取流程中的位置
data test;
input Name_Male $15. +2 Number +1 Name_Female $20.;
cards;
LOUIE BLACKWELL 76 ALI DALTON
CADE NIXON 123 GABRIELLA MCKAY
QUINCY STARK 6843 JOSIE LOPEZ
;
run;- 首先檢查要輸入的資料,每筆觀察值的分隔位置是不是相同的
- 在Input敘述句後同樣先輸入變數名稱
- 如果是文字變數,此時在輸入$後還需要輸入1個「數字」與1個「.」,這表示要讀取多少長度的字元
- 在「Name_Male」後方輸入$15.,這表示每一筆觀察值的Name_Male要讀取共15個長度的字元,這個長度是依據最長一列資料的Name_Male值而定
- 接著暫時先不要輸入下一個變數名稱,這時候我們要到cards敘述句中查看讀取完「Name_Male」後到下一個變數最早遇到那列資料共間隔幾個字元,可以看到最早遇到是第3列的「6843」的「6」,為第17個字元,17-15共間隔2個字元,所以我們需要在敘述句中間輸入「+2」,表示要求pointer-controls往右2個位置後再繼續讀取下一個變數
- 其他變數依此類推
Named Input
最獨樹一格的Input方式,但不用跟Column Input、Formatted Input去算幾個字元
在Input敘述句中每個變數後面需加上1個「等號(=)」,資料當中每個值前面要放入對應的變數名稱與1個「等號(=)」
是除了資料有特定限制的格式外,僅次於List Input簡單的方法
data test;
input Name_Male= $ Name_Female= $;
cards;
Name_Male=LOUIE BLACKWELL Name_Female=ALI DALTON
Name_Male=CADE NIXON Name_Female=GABRIELLA MCKAY
Name_Male=QUINCY STARK Name_Female=JOSIE LOPEZ
;
run;- 首先檢查要輸入的資料,每列資料中的觀察值前面是否有放入對應的變數名稱與1個「等號(=)」
- 在Input敘述句後同樣先輸入變數名稱,並且加上與1個「等號(=)」
- 如果是文字變數,此時需要再輸入1個$
Pointer-Controls
當遇到髒資料或是並非常見的格式時,可以使用Pointer-Controls,它能用來控制SAS使用Input敘述句時指定讀取的位置,依照功能又分為Column Pointer-Controls與Line Pointer-Controls兩種
| 功能 | 絕對位置 | 相對位置 |
| Column Pointer-Controls | @n | +n |
| @numeric-variable | +numeric-variable | |
| @(expression) | +(expression) | |
| Line Pointer-Controls | #n | / |
| #numeric-variable | ||
| #(expression) |
Column Pointer-Controls範例
今天有以下的資料:
00156 714954
00276 528121
00392 748866
希望讀取最後的資料為下圖

data test(drop=n);
n=9;
input No $3. +0 A1 2. @7 B1 2. @n C1 2. @(n+2) D1 2.;
cards;
00156 714954
00276 528121
00392 748866
;
run;- 共有No這一個文字變數與「A1、B1、C1、D1」這四個數值變數要讀取
- 在Input敘述句中首先定義No的文字長度為3,所以會分別讀取三筆觀察值「001」、「002」、「003」
- 接著因為No變數的值與A1變數相鄰,所以可以選擇「填上+0(冗贅)」或是「不填入值(SAS會自動判斷相鄰)」,接著放入A1與2.,表示A1變數要從前一個變數向右移動0個列相對位置後、讀取2個長度
- 接著A1變數的值與B1變數相鄰一個空白,可以改直接指定列絕對位置,先輸入@7,接著放入B1與2.,表示B1變數要從第7個列絕對位置讀取,讀取2個長度
- 接著B1變數的值C1變數相鄰,同樣可以直接指定列絕對位置,此時如果知道絕對位置,可以透過使用「@n」這個方式,將預先知道的值存到變數中進行使用,輸入@n,接著放入C1與2.,表示C1變數要從第n(n=7)個列絕對位置讀取,讀取2個長度
- 接著C1變數的值D1變數相鄰,同樣可以直接指定列絕對位置,此時可以透過使用「@n+2」這個方式,將上一個變數的值加上一個變數的長度,先輸入@(n+2),接著放入D1與2.,表示D1變數要從第n+2(n=9)個列絕對位置讀取,讀取2個長度
Line Pointer-Controls範例
今天有以下的資料:
001
56
71
49
54
002
76
52
81
21
希望讀取最後的資料為下圖

data test(drop=n);
n=1;
input No $ / A1 #3 B1 #4 C1 / D1;
cards;
001
56
71
49
54
002
76
52
81
21
;
run;- 共有No這一個文字變數與「A1、B1、C1、D1」這四個數值變數要讀取
- 在Input敘述句中首先定義No為文字格式,接著輸入「/」表示下一個變數A1在當前行下一行讀取,此為行相對位置
- 接著B1變數在第3行,此時可以直接指定行絕對位置,輸入#3,表示B1變數的值要在這一筆觀察值的第3行讀取
- 接著C1變數在第4行,此時可以直接指定行絕對位置,輸入#4,表示C1變數的值要在這一筆觀察值的第4行讀取
- 接著D1變數在第5行,改使用行相對位置,輸入「/」,表示D1變數在當前行的下一行讀取
- 在讀完第一筆觀察值的5個變數,接著向下讀第2筆觀察值,同理
資料讀取錯誤時 – 調整修飾符(Modifiers)
當讀取的資料本身不完整、有缺失時,卻又不想看見日誌中出現好幾列的「NOTE: Invalid data for …」,此時可以使用?與??這兩個修飾符
?:阻止日誌出現「NOTE: Invalid data for …」的所有訊息,並且自動變數「_ERROR_」會被設為1的值
data test;
input No $ A1 Str ?;
put _error_=;
cards;
001 56 A
002 76 B
003 92 C
;
run;
??:阻止日誌出現「NOTE: Invalid data for …」的所有訊息,並且防止自動變數「_ERROR_」被設成1的值,可以避免程式執行到一半因為讀取資料錯誤而中止
data test;
input No $ A1 Str ??;
put _error_=;
cards;
001 56 A
002 76 B
003 92 C
;
run;
Infile敘述句
Infile敘述句在讀取資料時需與Input敘述句搭配使用,它通常是用來讀取外部的文字檔,像是txt、csv,這種以分隔符號間隔的資料,可以說因為Infile敘述句與Input敘述句搭配使用,讓讀取外部資料這件事變得完美
假設今天有一個sample的txt檔,裡面紀錄了這3筆資料,並把它存放在E:\test路徑下

data test;
infile "E:\test\sample.txt" DLM=",";
input No $ A1 B1 C1;
run;- 在Infile敘述句中以單引號或雙引號包裹住「檔案路徑(包含副檔名)」
- 由於在上方的txt檔看到資料是以逗號為分隔,所以使用DLM這個選項
- 先輸入「DLM=」
- 在DLM=後方輸入「”,”」,意即要讀取的資料是以逗號為分隔符號
- 接著Input敘述句則是依照txt檔如何儲存資料而定,這邊我們使用List Input作為示範
在日誌中我們會看到類似如下的資訊:

Options
在Infile敘述句中可以加上Options,可以調整Infile敘述句的功能
常用的Infile敘述句 – Options
| Options | 說明 |
| DELIMITER= | DLM= | 指定讀取資料時辨別的分隔符號 |
| DSD | 將2個連續的分隔符號視作遺漏值 |
| MISSOVER | 限制SAS讀取資料為一筆觀察值一行,當該行讀取到最右邊時,沒有值的變數會變成遺漏值 |
| FIRSTOBS= | OBS= | 從第nth筆觀察值開始讀取;讀取到第nth筆觀察值 |
DELIMITER | DLM
data test;
infile cards dlm="*";
input No $ num Str $;
cards;
001*56*AAAAA
002*76*BBBBB
003*92*CCCCC
;
run;- 假設現在有一群資料以「*」為分隔符號
- 在Infile敘述句後方先放入「dlm=」
- 接著在「dlm=」後方放入由雙引號包裹的*符號
DSD
data test;
infile cards dsd;
input No $ A1 B1 C1 D1 E1;
cards;
001,56,,49,54,87
002,76,52,,21,76
003,92,74,88,,77
;
run;- 假設現在有一群資料以「,」為分隔符號,發現有資料是遺漏值
- 在Infile敘述句後方先放入「dsd」
- 在程式執行完成後,會看見連續2個分隔符號的值會被設為遺漏值(不管是文字或數值變數)

MISSOVER
data test;
infile cards missover;
input No $ A1 B1 C1 D1 E1;
cards;
001 56 71 49 54
002 76 52
003
;
run;- 假設現在有一群有許多遺漏值的資料
- 在Infile敘述句後方先放入「missover」
- 在程式執行完成後,未讀取到值的變數會被設為遺漏值,接著繼續讀取下一筆觀察值
- 下面的第一張圖是未輸入missover Option的結果,觀察值筆數與值都與我們預期不符
- 下面的第二張圖是輸入missover Option的結果,與我們預期結果相符
未輸入missover Option

輸入missover Option


謝謝閱讀這篇文章,有問題歡迎在下方留言


